




.svg)





by Huma Zafar
If you’ve got a card at one of our many participating libraries, you’re likely familiar with the BiblioCommons online platform. At BiblioCommons, we build products that help public libraries extend their communities from inspiring physical spaces to equally beautiful and welcoming digital spaces. We call these interconnected, online communities “The Commons”. With this blog, we, the BiblioCommons engineers, hope to talk about the work we do in building and maintaining the tech that powers The Commons.
To give you an idea of what engineering at BiblioCommons looks like in 2017, here's a brief introduction to our product stacks.

Our primary product, BiblioCore, is a discovery layer that enhances the search and user engagement capabilities of a library’s catalog. It’s a multi-tenant SaaS application, built with JRuby on Rails and Java 8, but we’re in the midst of migrating this to a React/Redux front-end, on top of an Express/Node framework that will act as an API gateway to our back-end. We’ve been simultaneously exploring a Domain Driven Design-based reorganization of our back-end, using Spring MVC to create RESTful Java APIs, and Spring Boot and Spring Cloud to develop microservices. We use TeamCity as our CI server, and our core application is deployed using Docker containers and Ansible.
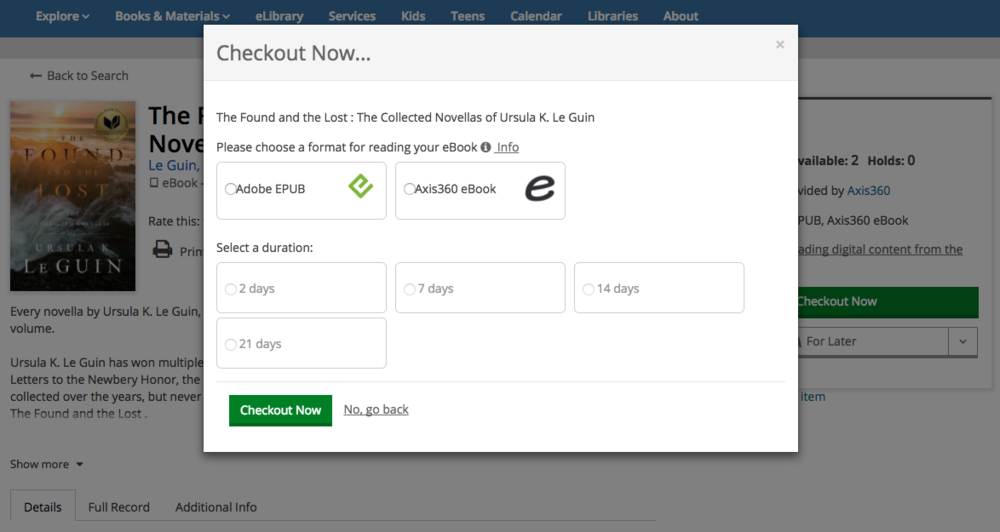

The Core application is supported by a few other components, most important of which are offline Java services we’ve built for processing high volumes of data, which run on separate clusters and receive messages from the app via ActiveMQ. To handle the number of requests we receive from millions of monthly users, we supplement our application with a Memcached cluster. We’ve also built integrations for several third-party systems to support a wide range of library features for our customers and their patrons.
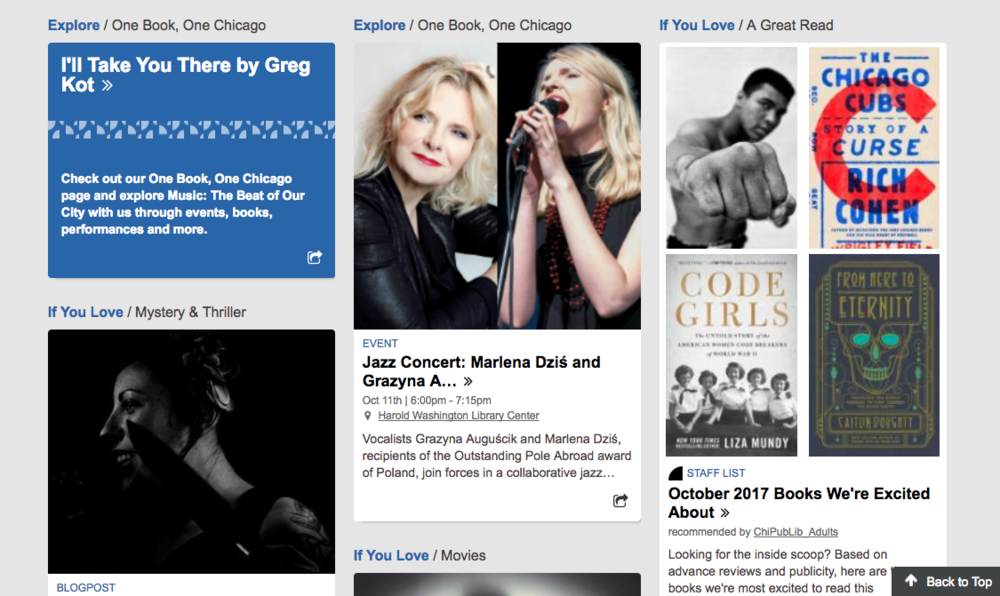

Our two other main products are BiblioWeb and BiblioEvents, both of which fully integrate with BiblioCore. BiblioWeb is also a containerized Docker app built using Sass, Gulp, and RequireJS on top of (always up-to-date!) WordPress. It runs on six LAMP servers, each of which is equipped with a Varnish cache. We use Amazon CloudFront as our content delivery network, Sendgrid for emails, and VWO for A/B testing. All development on the BiblioWeb team follows PSR1/2 coding standards and is tested using the Codeception framework to ensure high quality code.
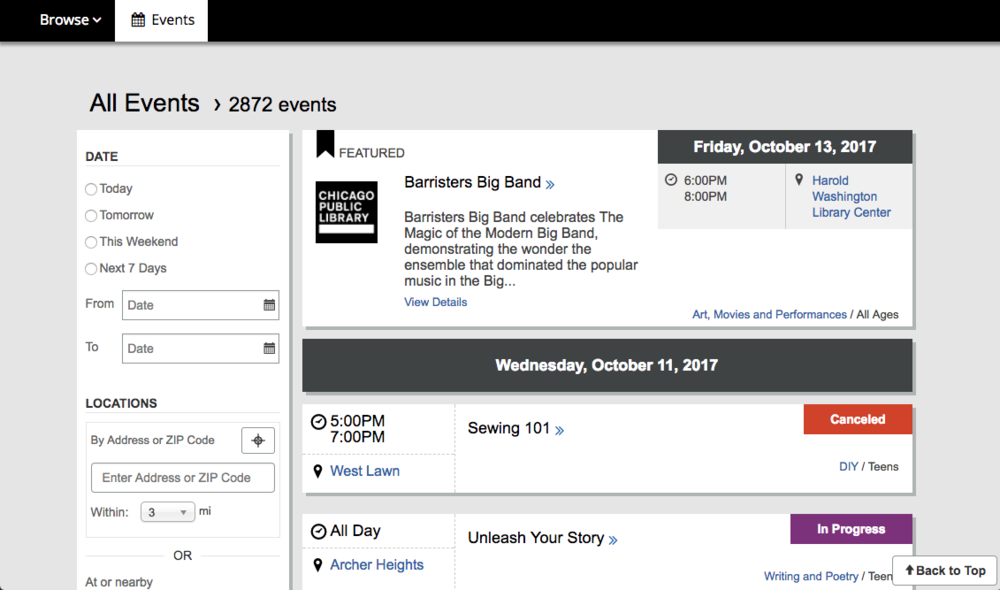

BiblioEvents is primarily a JavaScript single-page application; the client-side is an Ember app built with Bootstrap, Moment, Handlebars, and LESS, while the server-side runs on NodeJS with Express, MongoDB, and a Redis cache. BiblioEvents uses Mocha and Codeship for testing and CI, and both BiblioEvents and BiblioCore use SolrCloud to power their versatile search features.
With all of these moving pieces, effective monitoring is crucial to making sure our products stay reliable and performant. We use Zabbix, New Relic, Prometheus, and Sumo Logic for monitoring the status of different parts of our application, and Hystrix dashboards for our circuit breakers to give us insight into our third-party integrations. We combine these tools with Pagerduty alerting so that we can always respond promptly to any issues.
We’re a team that gets to work with a variety of interesting technologies, and we're very excited to start using this space to talk about the broad range of complex problems we tackle—from implementing large-scale website optimizations to sweating the details of novel interfaces, to all the various challenges in between. We look forward to sharing our progress as we continue to grow and develop innovative public library tech, and we hope that you'll join us here in our explorations!
Huma is a platform engineer on the Core Operations team at BiblioCommons and a trained library technician. Her work is split between third-party integrations, internal tool development, code maintenance, and daydreams of functional Java.